Yarn Cluster Mode Configuration¶
Overview¶
In order for the yarn cluster mode to work to validate the Spark processor, the JSON policy file has to be passed to the cluster. In addition the hive-site.xml file needs to be passed. This should work for both HDP and Cloudera clusters.
Requirements¶
You must have Kylo installed.
Step 1: Add the Data Nucleus Jars¶
Note
This step is required only for HDP and is not required on Cloudera.
If using Hive in your Spark processors, provide Hive jar dependencies and hive-site.xml so that Spark can connect to the right Hive metastore. To do this, add the following jars into the “Extra Jars” parameter:
/usr/hdp/current/spark-client/lib (/usr/hdp/current/spark-client/lib/datanucleus-api-jdo-x.x.x.jar,/usr/hdp/current/spark-client/lib/datanucleus-core-x.x.x.jar,/usr/hdp/current/spark-client/lib/datanucleus-rdbms-x.x.x.jar)
Step 2: Add the hive-site.xml File¶
Specify “hive-site.xml”. It should be located in the following location:
Hortonworks
/usr/hdp/current/spark-client/conf/hive-site.xml
Cloudera
/etc/hive/conf.cloudera.hive/hive-site.xml
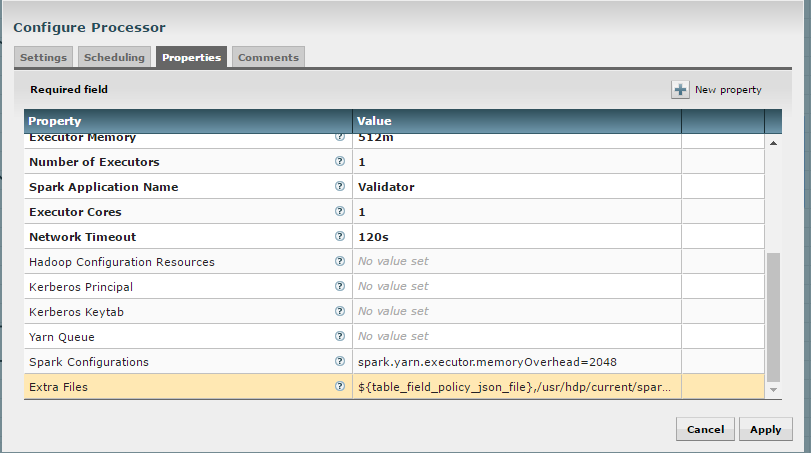
Add this file location to the “Extra Files” parameter. To add multiple files, separate them with a comma.

Step 3: Validate and Split Records Processor¶
If using the “Validate and Split Records” processor in the standard-ingest template, pass the JSON policy file as well.